
kaiyun认证通过不错考查业务数据-kaiyun网页登陆入口
一、业务需求
布景评释
当今在底层数据库建树当中,如故存在了集成好的梧桐数据库以及历史使用的hadoop集群。基于现存业务,需要使得已有的梧桐数据库可考查hive。原因如下:
1. 详细查询才气建树:在实践应用中,用户可能同期存在hadoop集群和MPP集群,MPP数据库擅长结构化处理且应用友好,而Hive则专注于历史数据的批处理查询。因此,将MPP数据库与Hive集成,不错充分应用两者的上风,慷慨用户千般化的查询需求。
2. 数据分享与整合:跟着企业数据量的束缚加多,数据频频散播在不同的系统和数据库中。通过将MPP数据库与Hive集成,不错杀青数据的分享与整合,使得用户梗概在一个平台上考查和分析来自不同数据源的数据。
二、有规划概述

1. 通过可插拔元数据框架分享Hive元数据。
梧桐数据库动作纯盘算引擎,无需创建外在杀青对Hive数据的考查或关联盘算,传统的数据库可能通过connector有规划来杀青,然则这种花式使用起来性能很差。梧桐数据库盘算引擎不错通过分享HMS(Hive Metastore)元数据,径直考查Hive在HDFS上数据文献的神气加快考查性能,何况不错杀青库内的关联盘算。
出于安全商酌,一般皆确认过kerberos认证来考查hive库。
注:业务田户使用集团hive用到两种单子,一种是考查hive数据需要集团分拨的keytab文献去认证krb5.conf,认证通过不错考查业务数据,然则要考查hive的metadata,这是另外一种单子,需要再央求,这个单子认证过了之后,hive上的表相等于梧桐db的一张external table,即是浅薄作念一下映射。然则需要提防的是,考查速率较慢(数据量大的情况下),当今若是制作的表为readable external table,查询就很慢,在存在writeable external table这种业务的情况下,速率细目会更慢。
1. 自动感知Hive表schema的变化。
基于外在的有规划,频频需要删除表并再行建立以感知变化。梧桐数据库领受了分享Hive元数据的想路。将数据库的元数据剥离,整个依赖于Hive的HMS,通过这种花式,咱们不错原生地感知Hive表的Schema变化。
2. 买通Ranger权限对接杀青对Hive表列级权限摈弃。
梧桐数据库还不错与Hive权限进行对接买通。举例,若是Hive使用Ranger作念权限摈弃,不错与Ranger进行对接,杀青列级权限摈弃。
3. 兼容Hive分区表。
Hive原生的分区表不错无缝对接到梧桐数据库中。针对Hive表进行DB侧的统计信息网罗和分析操作,何况不错应用梧桐数据库的散播式特质和优化要领来普及查询性能和并发处理才气。
三、操作武艺
修改配置
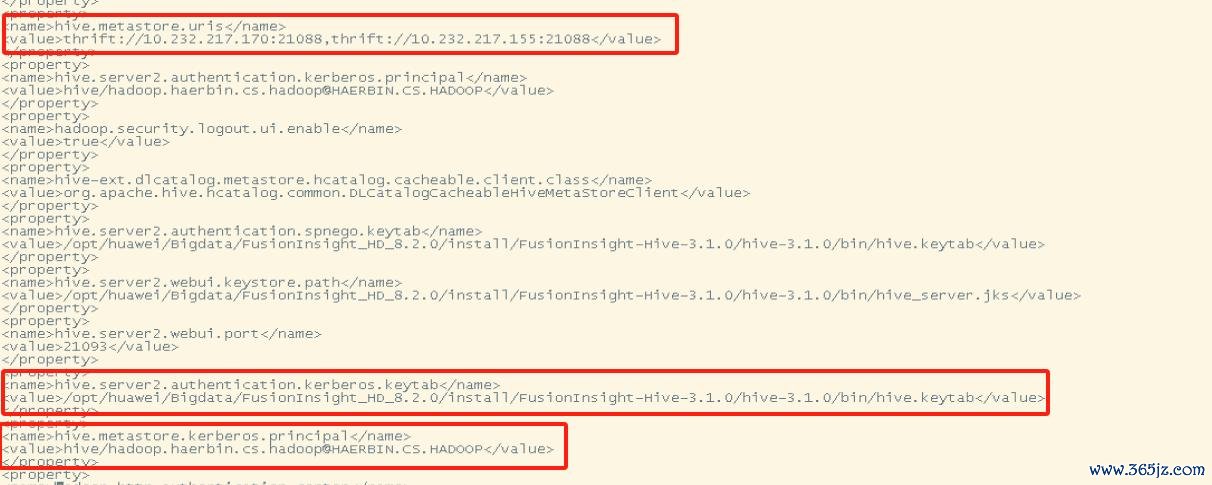
1. 获得客户hive相关信息
从客户的hive-site配置中获得metastore的hms、keytab、principal等信息,如下图所示:
2. 革新梧桐数据库相关配置信息(旧版)
证据客户hive-site配置中hms的ip端口、keytab、三段式principal,修改hdfs-client.xml配置,加多以下配置(不需要重启或者reload集群)
<property> <name>ip:port.hadoop.security.authentication</name> <value>kerberos</value></property><property> <name>ip:port.hadoop.security.token.lifetime</name> <value>604800000</value></property><property> <name>ip:port.hadoop.security.ticket.lifetime</name> <value>604800000</value></property><property>
3. 革新梧桐数据库相关配置信息(新版)
<property> <name><username>.hms.hive.security.authentication</name> <value>kerberos</value><property><property> <name><username>.hs2.hive.security.authentication</name> <value>kerberos</value><property><property> <name><username>.hms.hive.security.keytab</name> <value>/usr/local/oushu/conf/oushudb/hive.keytab</value></property><property> <name><username>.hms.hive.security.principal</name> <value>hive@OUSHU907381.COM</value> --<value>hive/host@OUSHU907381.COM</value></property><property> <name><username>.hs2.hive.security.keytab</name> <value>/usr/local/oushu/conf/oushudb/hive.keytab</value></property><property> <name><username>.hs2.hive.security.principal</name> <value>hive@OUSHU907381.COM</value> --<value>hive/host@OUSHU907381.COM</value></property><property> <name><username>.hms.hive.connection.url</name> <value><ip>:<port>,<ip>:<port>,...</value></property><property> <name><username>.hs2.hive.security.instance</name> <value></value></property>
示例:
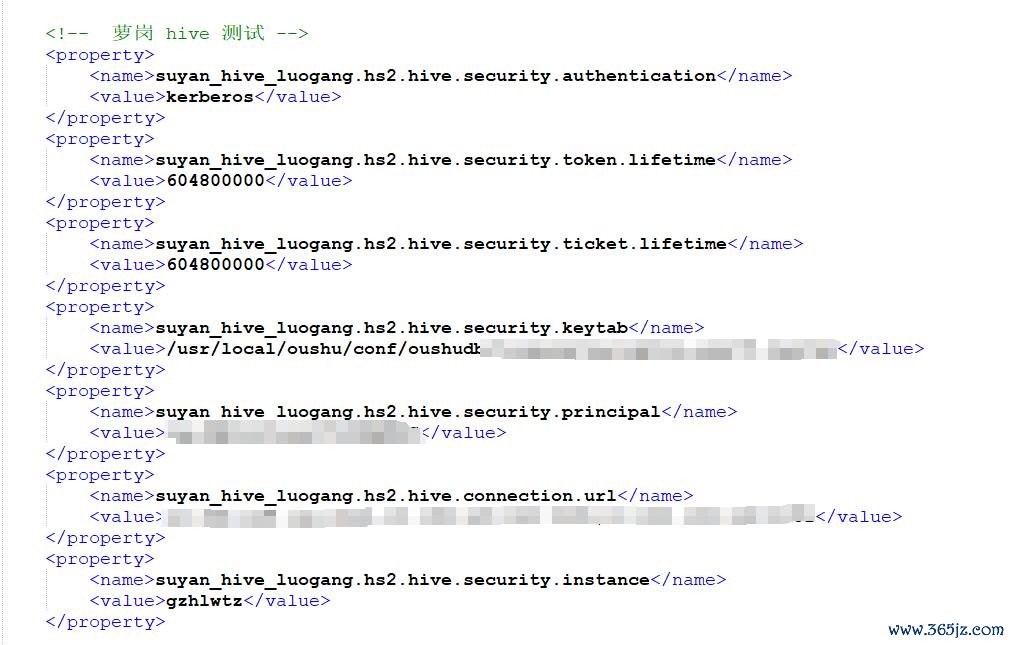
对应底下

四、应用场景
1. 及时与历史数据整合
在某些业务场景中,用户需要同期处理及时数据和历史数据。梧桐数据库不错处理及时数据,而Hive则隆重存储和治理历史数据。通过将梧桐数据库与Hive集成,不错杀青及时数据与历史数据的无缝整合,慷慨用户千般化的数据处理需求。
2. BI报表生成
在BI(交易智能)领域,MPP数据库与Hive的集成不错辅助快速生成复杂的报表和相貌盘。MPP数据库的高性能不错确保报表生成的及时性和准确性,而Hive则提供了丰富的数据源和查询才气,使得BI应用愈加生动和浩荡。
3. 跨部门数据分享
在大型企业中,不同部门可能使用不同的数据库系统来存储和治理数据。通过将MPP数据库与Hive集成,不错杀青跨部门数据的分享和整合,冲突数据孤岛,促进数据在企业里面的运动和应用。
4. 多源数据整合
在数据分析和挖掘经由中,频频需要整合来自多个数据源的数据。Hive不错动作数据整合的要害,将不同数据源的数据存储在Hadoop集群中,并通过MPP数据库的考查才气,杀青多源数据的整合和查询。
5. 复杂查询优化
梧桐数据库通过并行处理机制,不错显赫普及复杂查询的践诺后果。当Hive中的查询请求变得复杂且耗时较永劫,梧桐数据库不错动作查询加快器,通过并行处理优化查询性能,缩小查询反当令辰。
6. 数据分析加快
在数据分析领域,梧桐数据库与Hive的集成不错加快数据分析经由。MPP数据库的高性能不错确保数据分析的及时性和准确性kaiyun,而Hive则提供了丰富的数据调和和盘算才气,辅助复杂的数据分析任务。


炒股一朝开了窍,东说念主生就像悟了说念。就在6年前,一个宁波的一又友,辞去铁饭碗,而去全职炒股,只因为真金白银回归了这6个炒股真理。顿悟了少走十年的弯路,注意护理保藏起来好好参谋。这些王人是经得起阛阓磨砺的炒股考验回归。你在书上是看不到真的切的常识干货。炒股不是一门常识,更像一门扩充的艺术。老马也曾说过这样一句话,企业家弗玉成听经济学家的,雷同,炒股也弗玉成信竹素上的常识。原因很大要,因为常识是四的,而行情是活的。是以说炒股更是一门艺术。我发现许多东说念主可爱参谋一线妙手的交割单,可是这些东说
查看更多
AF:=(COST(99)-COST(1));K1:STICKLINE(COST(99)-COST(95)AF,COST(99),COST(95),2,0),COLOREE0000;K2:STICKLINE(COST(95)-COST(90)AF ,COST(90),COST(95),2,0),COLORAA0000;K3:STICKLINE(COST(90)-COST(85)AF ,COST(90),COST(85),2,0),COLOR770000;K4:STICKLINE(COST(85)
查看更多
炒股一朝开了窍,非论什么行情皆不错作念到一通百通。投入股市仍是16年了,真金白银转头了计划牛熊的实用炒股口诀,淌若你也想跑在多量东说念主前边,那么以下的口诀谨记牢记在心。防御存眷储藏照拂。这些口诀诚然字数未几,然则字字珠玑。值得你去念念考和抓行。诚然口诀很马虎易懂,然则要想天真用在本色行情中,照旧有一定的难度的。有些口诀你需要联结本色的行情走势去默契口诀的含义。要不你很难默契其中的含义。不然基本皆是走马不雅花走一个过场。今天共享的口诀波及的面相比广,需要你很有耐性照拂学习。非论你是股市老油条照
查看更多
归拢利华将打包出售好意思妆品牌 为了聚焦高端赛说念,巨头们正在剥离平价产物线。 9月21日,归拢利华已聘用摩根士丹利和Evercore Inc.等投资银行,打包出售非中枢好意思容和个东说念主守护品牌,这个名为Elida Beauty的组合包囊括Caress、TIGI、Timotei、Monsavon等品牌,也包含了中国耗费者熟知的旁氏(Ponds)。 归拢利华此举与新上任的CEO司马翰(Hein Schumacher)关联。这位7月刚赴任的高管,脚下的着急方针即是应酬通胀压力同期精简业务。他在
查看更多

